
Esta es la continuación de un artículo anterior donde aprendíamos las diferencias entre un Sistema de Recuperación de información, uno de Extracción de Información y otro de Búsqueda de respuestas. En este segundo Capítulo nos vamos a centrar en las características básicas de un buscador y su funcionamiento interno. Voy a intentar escribirlo de forma que cualquiera pueda entenderlo.
Vamos a hacernos primero la pregunta de oro: ¿Cómo puede un buscador encontrar una palabra buscando en todas las páginas webs del mundo en menos de un segundo? . La primera idea que nos viene a la cabeza es que debemos guardar toda la información de texto útil en el servidor que va a hacer de buscador, de esta forma no tendremos que ir buscando por internet, lo cual es más lento. La información que guarda Google en sus servidores de forma local la podéis ver pulsando en el enlace de Caché que aparece al lado de cada página encontrada. El proceso mediante el cual se actualiza la Caché con los nuevos datos de Internet se conoce como Google Dance:
Aún así la cantidad de información que hay guardada es inmensa y buscar algo aunque sea de forma local es un proceso lento. Pensad lo que le cuesta encontrar un simple archivo en a vuestro ordenador, seguramente tarde más que Google en realizar una tarea similar. Esto se debe a que en nuestros ordenadores no tenemos la tecnología de los grandes buscadores de Internet.
¿Cuál es la forma más directa para hacer una búsqueda? Pues vamos mirando cada palabra del texto de una en una hasta que encontramos la palabra que buscamos. Esta técnica es conocida como Búsqueda secuencial. Por ejemplo, si tenemos la frase Perico va de paseo a la playa con Perica y estamos buscando Perica; el programa para buscar comenzará comparando con la primera palabra de la frase: ¿Perico == Perica? No, entonces continua con la segunda palabra: ¿ va==Perica? No. Así continuaría hasta ¿Perica==Perica? y terminaría la búsqueda con éxito.
El gran problema (entre otros) de esta forma de buscar es que si la cantidad de texto es muy grande y la palabra que buscamos se encuentra al final, deberemos recorrer todo el texto palabra por palabra obligatoriamente. Imaginaros buscar una palabra en todo Internet y tener la mala suerte de que Perica es la última palabra de la última web que miramos, la búsqueda tardará bastante tiempo aunque usemos un ordenador muy muy potente porque tendremos que ir comparando la palabra que buscamos con todas las palabras de Internet.
Veamos cómo buscaría Google si usara búsqueda secuencial. Las flechas Rojas indican las comparaciones de la palabra Einstein con cada palabra de las páginas webs, y las flechas Naranjas indican el movimiento entre las diferentes webs.
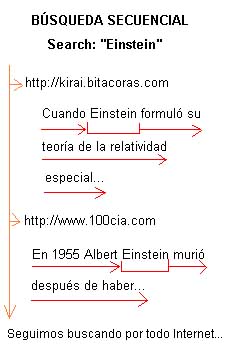
A partir de la imágen anterior vemos intuitivamente que mediante Búsqueda Secuencial debemos recorrer todas las páginas de la caché, es decir, todo Internet para obtener los resultados de una búsqueda.
Las Búsquedas secuenciales se usan para buscar cuando la cantidad de información a tratar no es muy grande. Por ejemplo, el buscador de tu propio blog, la búsqueda de vuestro procesador de Textos etc. ¿Pero que pasaría se nuestro blog tuviera 5 millones de posts y tuvieramos que buscar algo? Tardaría mucho en darnos la solución. Ese es uno de los problemas con el que se enfrentan los grandes buscadores, la cantidad inmensa de información.
Espero que me hayáis seguido todos hasta aquí porque ahora viene lo bueno. La forma de ahorrar tiempo es tratando la información previamente a las búsquedas. El proceso es el siguiente: Una vez tenemos ‘todo’ Internet guardado en local se realiza un proceso de Indexación. Con este proceso lo que se pretende es reducir al máximo la cantidad de información guardada. ¿Cómo lo conseguimos? Pensad en la cantidad de veces que se repite la palabra Einstein en Internet, ¿Es necesario que guardemos la palabra en nuestro disco duro 20 millones de veces? ¿No seria mejor guadarla Una sola vez e indicarle en que páginas web aparece?.
Fijaros que ahora en vez de guardar la palabra Einstein 20 millones de veces, solo la guardamos una vez. Ahora al hacer una búsqueda no se accede a la Caché, sino que se accede a los Datos Tratados. De esta forma si buscamos la palabra Einstein solo hay que hacer la búsqueda dentro de la lista de palabras y luego retornar las páginas en las que está. ¿Aún no veis la ventaja? Antes teníamos que ir comparando la palabra que buscamos con todo el texto de Internet, ahora solo tenemos que comparar con todas las palabras posibles ya que hemos eliminado todas las repeticiones.
Para verlo más claro veamos como sería una búsqueda usando los datos tratados. En esta ocasión vamos a buscar la palabra Gödel. Las flechas rojas indican las diferentes comparaciones que se van haciendo con cada palabra indexada, y la flecha naranja indica el resultado de la búsqueda.
Fijaros que ahora no tenemos que buscar dentro del texto de las páginas. Solo tenemos que ir mirando palabra a palabra y si no interesa pasamos a la siguiente, sería una busqueda secuencial con pocos datos. Este proceso es muchísimo más rápido que una búsqueda secuencial dentro del texto de todas las páginas y añadiendole ciertas mejoras se puede convertir en algo ‘parecido’ a Google. Una de las mejoras más evidentes es usar técnicas de busqueda más avanzadas usando los Datos Tratados.
De esta forma Google reduce la cantidad de información donde tiene que buscar de varios miles de Gigas de texto a unos pocos Gigas de palabras tratadas. Estos pocos Gigas se pueden cargar en memoria (Necesitan servidores bastante potentes) y así hacer las búsquedas muy rápidamente.
Puff. En teoría ya tenéis los conocimientos necesarios para programar un Sistema de recuperación de Información muy básico. Pensaba que sería más sencillo de explicar, espero que os haya quedado más o menos claro. Ya podéis preguntar y criticar 😉
Muy ilustrativo 😉
Ahora solo te queda explicar los algoritmos de DataMining, PageRank y algo de la heurística del tito Google.
Enhorabuena por el post.
Calificación: Muy ‘Internetsante’
Sipes, eso lo dejamos para el Capítulo 3. No creo que me meta con algoritmos, seguramente explique un poquito de PageRank que es más entretenido 🙂
Nunca se me hubiese ocurrido pensar cómo busca un buscador como Google… 😛
A mi se me ocurrió que era mas facil comparar un número que una palabra, entonces, merecía la pena tener una tabla que relacionara números y palabras, tal que 1 = Albin y 99999 = Zarzuela. Luego otra tablita tal que http://www.ocio.com estuviera relacionada con el número 99999. Si alguien quiere buscar «Zarzuela» busco su número asociado, y luego páginas que tengan asociado ese número… eso pensé yo … ya veis :o|
Muy bueno el artículo, Héctor, o al menos para los que no sabemos nada de esto como yo 🙂 Ya me gustaría a mí escribir cosas de estas en mi blog… jejeje.
Y es verdad, menuda ventaja lo de indexar. Yo utilizo índices al programar, pero hasta ahora no conocía bien cuál era el funcionamiento interno. Espero con ganas el siguiente capítulo 😛
Sencillamente genial Kirai. De lo mejorcito que he leído últimamente por las bitácoras. Trmendamente currado y has hecho fácil, lo difícil. Enhorabuena, esto te ha dado mil puntos extra y un bonus.
Ostias tio, Da miedo leerlo por lo largo que es, pero merece la pena ^_^
Salu2 Caleidos
Muy claro y bien explicado para los ignorantes como yo.Gracias.
^_^ gracias, tampoco será para tanto. Hay que seguir mejorando la calidad, aunque hacer un artículo de estos da bastante trabajo y va a ser complicado superarlo.
Felicidades!!! además de un tema interesantísimo has sabido condensar en pocas palabras la complejidad de un buscador.
Con tu permiso, tomo prestadas algunas de tus palabras para escribir (reescribir) un post al respecto.
¿Para cuando mas?? 🙂
Un honor que me reescribas ;). El siguiente artículo cuando tenga un ratito jeje
A mi también me ha gustado mucho 🙂 No tengo mucha idea de buscadores, ni de búsquedas (vamos, solo los tres métodos que te enseñan en 1ro). Me sonaba lo de la indexación de los buscadores pero lo relacionaba con ID’s que generaban ellos, google por ejemplo, aplicado a enlaces. Es ingenioso sin duda; y esto imagino que es lo más básico, la de filigranas que harán bichos como
El OráculoGoogle…¡Saludos!
Tio, no se como he llegado a tu pagina pero se ve que te gusta el tema, eres un geek de cojones, gracias a gente como tu gente como yo se entera de como funcionan los ordenadores. Por cierto, yo tambien me voy a asia, pero a primeros de junio.
Tio, no se como he llegado a tu pagina pero se ve que te gusta el tema, eres un geek de cojones, gracias a gente como tu gente como yo se entera de como funcionan los ordenadores. Por cierto, yo tambien me voy a asia, pero a primeros de junio.
Comment by tito 5/19/2004 @ 11:57 am